Ceph架构、原理和集群搭建
Ceph 介绍
架构
当有大量的小文件时,基于有中心架构的 HDFS 的 Name Node 会有很大的压力。
Ceph 是无中心架构的典型,取消了 HDFS 那样的集中式元数据存储。客户端通过一套算法(Crush)在本地计算出写入数据的存储位置,直接与存储节点(数据节点)交互。
仅 Ceph 块设备(RBD)和对象存储(RGW)没有元数据中心节点,文件存储(FS)还是有的,使用 MDS 服务集中存储元数据。

Ceph 中的核心组件包括:
- Mon(itor):维护 Monitor Map、OSD Map、PG Map、CRUSH Map 等各种维护存储集群状态的图表。(这些图表保存着其各自的每一次状态变更,称为 Epoch)
- OSD:Object Storage Device。存储数据、管理磁盘、读写数据。OSD 服务处理数据的复制、恢复(Recovery)、回填(Backfilling)、再均衡(Rebalance)等任务。还会检测其他 OSD 的状态并打包上报给 Mon。
- MDS:Metadata Server。负责 CephFS 集群中文件和目录的管理,记录数据的属性,如文件存储位置、大小、存储时间等,同时负责文件查找、文件记录、存储位置记录、访问授权。(有主备机制,主 MDS 故障之后,其他 Standby 的 MDS 会顶上)
- RADOS:包含 Mon、OSD、MDS。本质为一套分布式数据存储系统。Ceph存储中所有的数据都以对象形式存在,RADOS 负责保存这些对象。RADOS 层可以确保对象数据始终保持一致性。Ceph 其实是对 RADOS 的二次封装。
- RBD:提供可靠的分布式、高性能块存储逻辑卷(Volume)给客户端使用。写入 RBD 设备的数据以条带化的方式存储在 Ceph 集群的多个 OSD 中。
什么是条带化?

基本思想是:以轮转方式将磁盘阵列的块分布在磁盘上。
- RGW:RADOS Gateway。提供对象存储服务。支持 Amazon S3 的 API 调用方式。
- CephFS:提供与 POSIX 兼容的文件系统。
寻址方式

假设要存一个 1GiB 的文件。
Ceph 客户端持有一个 Cluster Map(初始化时就会向 Moniter 服务获取最新的 Map,然后采用反向订阅机制,仅在 Cluster Map 变化时,Mon 会主动推送)。
只要根据这个 Map 和文件的一些信息(如文件名和文件大小)就能得到这个文件的每个 Object 所在的 OSD 的 ID,然后直接与其通信。
一个文件对应一个唯一的 ino 。
这个文件首先在 Ceph 中被切割成多个 Object,用 ino+ono 标识。
然后通过对这个标识 hash 来分到不同的 PG 中,得到 PGID(每个 Object 分配一个 PG。一般来说,这样计算之后得到的 PGID 在大规模数据量看来会是均匀分布的)。
PG是一个为方便管理 OSD(对象存储设备) 而设置的一个抽象概念,一个PG中有多个 OSD,一个 OSD 也会承载多个PG。
得到 PGID 后,用 CRUSH 算法带入 PGID 得到多个 OSD 存入。
PG、PGP 和 OSD
由 PG 映射到数据存储的实际单元 OSD 中,该映射是由 CRUSH 算法来确定的。
使用 CRUSH 算法相对于使用 Hash 算法的好处:
- CRUSH 具有可配置特性,可根据配置参数决定OSD的物理位置映射策略;
- CRUSH具有特殊的“稳定性”,当系统中加入新的 OSD 导致系统规模增大时,大部分 PG 与 OSD 之间的映射关系不会发生改变,只是少部分 PG 的映射关系会发生变化并引发数据迁移(Straw 和 Straw2)
PG 是用来存放 Object 的,PGP 相当于是 PG 存放 OSD 的一种排列组合。一般来说应该将PG和PGP的数量设置为相等。
> ceph osd pool create testpool 6 6
1.1 75 [3,6,0]
1.0 83 [7,0,6]
1.3 144 [4,1,2]
1.2 146 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
> ceph osd pool set testpool pg_num 12
1.1 37 [3,6,0]
1.9 38 [3,6,0]
1.0 41 [7,0,6]
1.8 42 [7,0,6]
1.3 48 [4,1,2]
1.b 48 [4,1,2]
1.7 48 [4,1,2]
1.2 48 [7,4,1]
1.6 49 [7,4,1]
1.a 49 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
> ceph osd pool set testpool pgp_num 12
1.a 49 [1,2,6]
1.b 48 [1,6,2]
1.1 37 [3,6,0]
1.0 41 [7,0,6]
1.3 48 [4,1,2]
1.2 48 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
1.7 48 [1,6,0]
1.6 49 [3,6,7]
1.9 38 [1,4,2]
1.8 42 [1,2,3]
可以看到:
- PG 是指定一个 Pool 中存储对象的”目录”有多少个, 而 PGP 指定 OSD 的排列组合有多少组
- ⚠ PG 的增加会引起 PG 内维护对象的分裂, 不会触发 Rebalance
- ⚠ PGP 的增加可能会改变一个 PG 所映射的 OSD 的组合,会导致 Rebalance
PG 与 Pool

CRUSH
CRUSH有两个关键参数:Cluster Map 和 Placement Rules。
Cluster Map
反映整个 Ceph 存储系统层级(共 11 个层级)的物理拓扑结构。
包含OSD守护进程的层级信息。
由 Device(OSD)和 Bucket(存 OSD 的容器,可以是很多东西,如 Host,Rack 机架)这两个基本元素形成一整个结构体系。

Device 有权重概念。越高的权重在选 Device 时就会更多地选到这个 Device 上。Bucket 也有权重概念,其最终权重是它的权重和它所包含的 Device 权重的总和。 
Placement Rules
决定了一个 PG 如何选择 OSD。通过自定义 Placement Rules,用户可以设置副本在集群中的分布
定义类似:

PG 选出 OSD
四种 CRUSH 算法:
 常用(默认)Straw2。
Straw 算法过程:
max_x = -1
max_item = -1
for each item:
x = random value from 0..65535
x *= scaling factor
if x > max_x:
max_x = x
max_item = item
return item
(1)给出一个 PG_ID,作为 CRUSH_HASH 方法的输入; (2)CRUSH_HASH(PG_ID,OSD_ID,r)方法调用之后,得出一个随机数; (3)对于所有的 OSD,用它们的权重乘以每个 OSD_ID 对应的随机数,得到乘积; (4)选出乘积最大的 OSD ; (5)这个 PG 就会保存到这个 OSD 上。
Straw2 算法过程:
max_x = -1
max_item = -1
for each item:
x = random value from 0..65535
x = ln(x / 65536) / weight
if x > max_x:
max_x = x
max_item = item
return item
Straw 算法里面添加节点或者减少节点,其他服务器上的 OSD 之间会有PG 的流动(即数据的迁移);Straw2 算法里面添加节点或者减少节点,只会有 PG 从变化的节点移出或者从其他点移入,其他不相干节点不会触发数据的迁移。
Ceph 的 Luminous 版本开始默认支持 Straw2 算法。
PG 状态机
下面列出常见的 PG 状态。
Peering
等待 PG 包含的冗余组中所有对象达到一致性。I/O 阻塞。
Peered
等待其他副本(OSD 守护进程)上线。I/O 阻塞。
Degraded
PG 副本数 < 3
Recovery
Recovery 指对应副本能够通过日志(PGLog1)进行恢复,即只需要修复该副本上与权威日志不同步的那部分对象,即可完成存储系统内数据的整体恢复。
Recovery 有两种恢复方式:Pull(Primary 自身选择合适的副本拉取降级对象的权威日志),Push(主动)Primary 节点会先 Pull, 然后再 Push。
客户端读请求,待访问的对象在一个或者多个副本上处于降级状态,对应的读请求可以直接在 Primary 上完成,对象仅仅在副本上降级,无任何影响。如果 Primary 上也处于降级状态,需要等 Primary 完成修复,才能继续。
客户端写请求,待访问的对象在一个或者多个副本上处于降级状态,必须修复该对象上所有的降级副本之后才能继续处理写请求。最坏情况,需要先修复 Primary,再由 Primary 修复其他降级副本。
RBD
映射
通过 librbd、KRBD 等访问。一般选用前者。后者是 Kernel RBD,Linux 内部支持的,运行在操作系统内核态,需要部署在客户端节点的操作系统内核中。
librbd 按照使用方式又可以分为 QEMU+librbd、SPDK+librbd 和 NBD+librbd。
快照和克隆
快照只读,克隆可读写,Ceph RBD 设备的快照和克隆操作存在相关性,即克隆操作一定要基于某一已创建的快照进行。
Ceph RBD 的快照和克隆均采用 COW。这样也会有这个问题:当一个 RBD 上有较多层级的克隆卷时,对克隆卷进行读写时,可能会涉及较多层级的递归查询操作,会对克隆卷的性能产生不小的影响。(可解除克隆卷与原卷的依赖关系)
下面的图中,场景是新数据写入到已经有快照的源卷的第 6 块上。

- 这种方式很好地节省了空间,但这也会造成写放大,因此创建多个快照之后,对 I/O 性能的劣化效果会越来越明显。因为在为快照向新的物理空间复制出一份数据之后,还要为所有已创建的快照修改数据块的地址指针。
附 ROW 的机理图:

显然,ROW 不会造成写放大,因为新数据直接写到新块(7)上(假设新数据 I/O 落在原卷第 6 个块上)。但是这样源卷的存储物理空间发生了变化(原来的 6 现在指向 7)。
会劣化源卷的顺序读写。
RBD Cache
- 提供读缓存、写合并
- 存在内存中,有一定的可自定义的策略定时 Write Back。
- 支持 RWL,能大幅度提高IOPS,并且容灾性能++(需要特定硬件)
QoS
提供针对不同用户或不同数据流采用不同优先级的 I/O 读写能力服务策略。
- mClock
- dmClock
Burst I/O
Ceph RBD 设备突发能力的实现基于令牌桶。
Ceph测试集群搭建
3个虚拟机IP:
10.2.217.231(master),10.2.217.214,10.2.217.204
使用cephadm工具进行搭建。
- 修改主机名
hostnamectl set-hostname cephtest1 #其他2个同理
- 修改/etc/hosts文件(3个都要改)
...
10.2.217.204 cephtest1
10.2.217.231 cephtest2
10.2.217.214 cephtest3
- (可选)如果在你的公司内网部署,需配置yum repo源
#对于Redhat8,是这个文件,如果是CentOS,则是xxxCentOS.repo
vim /etc/yum.repos.d/8ASU7_Red.repo
# 直接append就行。需要redhat87、docker、epel的源
# 加完后记得makecache:
yum makecache
- 关闭防火墙、开启时间同步
systemctl disable --now firewalld
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
yum install -y chrony
systemctl enable --now chronyd
- 安装lvm2、python3、docker-ce
yum install -y lvm2
yum install -y python3
# 配置软链接
ln -s /usr/bin/python3 /usr/bin/python
yum install -y docker-ce
- cephadm安装(从这一步开始,只需要其中一台机器作为master来执行)
curl https://raw.githubusercontent.com/ceph/ceph/v15.2.1/src/cephadm/cephadm -o cephadm
chmod 777 cephadm && ./cephadm add-repo --release octopus
./cephadm install
- cephadm加载
mkdir -p /etc/ceph
cephadm bootstrap --mon-ip 10.2.217.231
稍等,就会出现如下信息:
Ceph Dashboard is now available at:
URL: https://cephtest1:8443/
User: admin
Password: f38lpz1yzj
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid e8aad788-418a-11ee-b97d-fa163e71b85a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
- 安装ceph-common
cephadm install ceph-common
- 加入其他机器到集群
# 其他机器重复这些操作
ssh-copy-id -f -i /etc/ceph/ceph.pub root@cephtest2
ceph orch host add cephtest2 10.2.217.214
# 加完之后输入ceph orch host ls,就可以看到刚刚加的机器。
[@cephtest1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
cephtest1 cephtest1
cephtest2 10.2.217.231
cephtest3 10.2.217.214
输入ceph orch ps可以看到运行着的容器。如果有error,说明部署操作有问题。
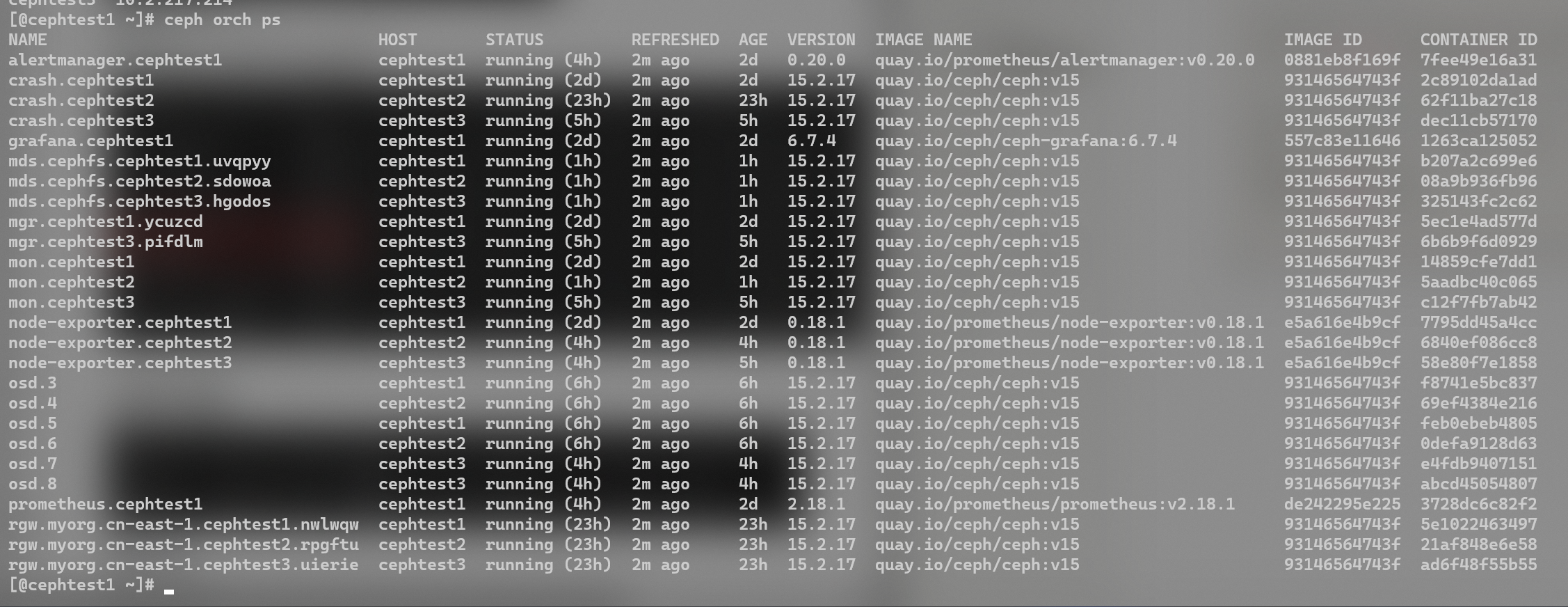
NOTE:ceph所有服务都是在docker内运行的,有monitor、crash、osd、rgw等服务(所以很吃内存)。结合近期踩过的坑,可以了解到启动的脚本其实是放在/var/lib/ceph/xxxx[集群id]/xxx[服务名称]/unit.run下的。master节点先通过ssh装载ceph相关服务,然后远程调用这个脚本来在这个节点上启动docker。
[@cephtest3 ~]# cd /var/lib/ceph/e8aad788-418a-11ee-b97d-fa163e71b85a/mon.cephtest3/ config kv_backend store.db/ unit.created unit.poststop keyring min_mon_release unit.configured unit.image unit.run
**NOTE2:如果见到哪个error了,直接在master上面通过诸如
**ceph orch daemon rm mon.cephtest2 —force的指令删除该daemon,然后再用类似的指令apply:ceph orch apply mon –placement=“cephtest1, cephtest2, cephtest3” (这里以重装monitor为例)
- 部署OSD
ceph orch device ls
# 如果没发现任何输出,没有任何可用的磁盘。
# 需要满足:
# 设备没有分区
# 设备没有LVM状态
# 设备不含文件系统
# 设备不含Ceph BlueStore OSD
# 设备大于5G
# 不得安装设备
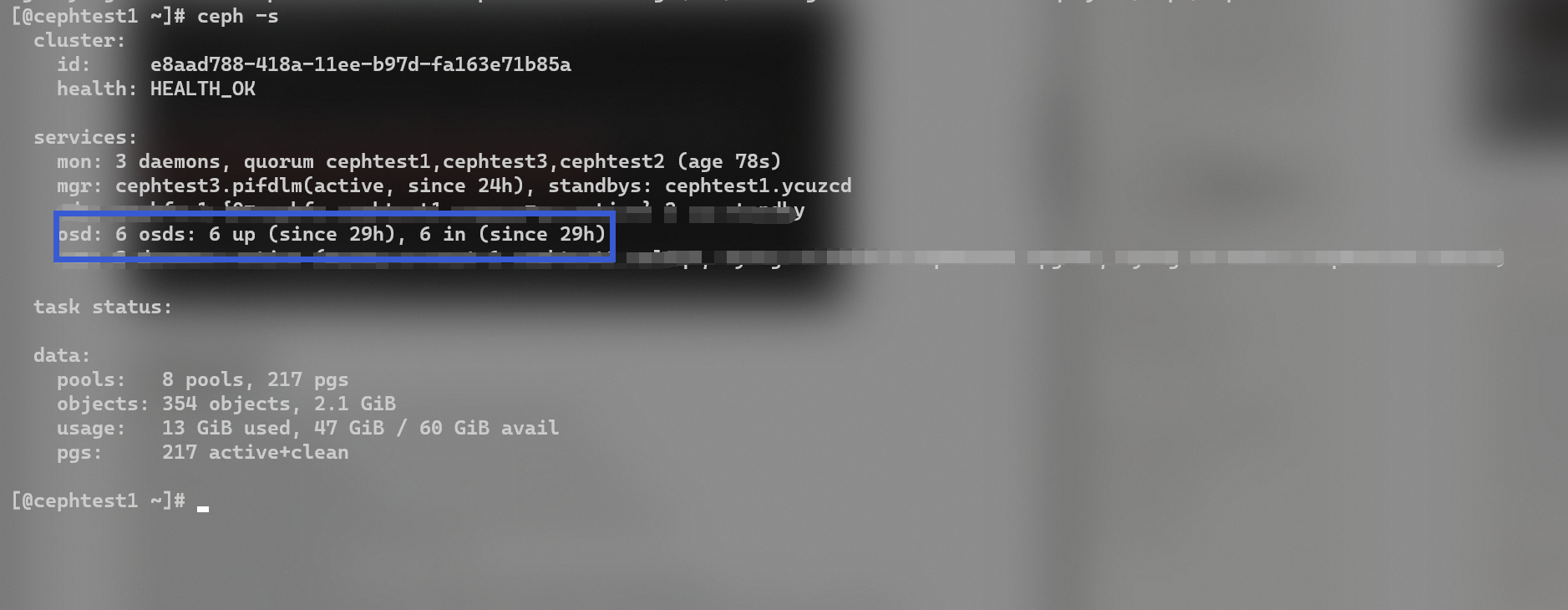
ceph orch apply osd --all-available-devices
ceph -s
如果发现所有设备均 avaliable no,可以使用
ceph orch device ls --wide --refresh
来查看原因。
osd: 6 osds: 6 up (since 29h), 6 in (since 29h)
- 部署MDS
ceph osd pool create cephfs_data 64 64
ceph osd pool create cephfs_metadata 64 64
ceph fs new cephfs cephfs_metadata cephfs_data
ceph fs ls
ceph orch apply mds cephfs --placement="cephtest1 cephtest2 cephtest3"
静待3分钟左右,然后输入docker ps | grep mds。

这一步完成之后,我们就已经可以正常使用Ceph了。在用户侧,可以直接连接RADOS上传文件。以下是上传文件的代码:
# 直连RADOS上传文件
import rados
import time
import uuid
cluster = rados.Rados(conffile='/etc/ceph/ceph.conf')
cluster.connect()
ioctx = cluster.open_ioctx('cephfs_data')
# 写入文件到集群中
def write_file(file_name):
# for i in range(1, 10):
start = time.time()
fn = file_name + "." + str(uuid.uuid4())
print("Start writing " + fn)
with open(file_name, 'rb') as f:
data = f.read()
ioctx.write_full(fn, data)
end = time.time()
print(fn + " is written. Time: " + str(end - start) + "s")
print("Speed: " + str(len(data) / (end - start) / 1024 / 1024) + "MB/s")
# 并发测试:开10个线程,每个线程写一个文件
import threading
threads = []
for i in range(1, 11):
t = threading.Thread(target=write_file, args=("OS.pdf",))
threads.append(t)
t.start()
# 列出池中的所有文件名
# ioctx = cluster.open_ioctx('cephfs_data')
# objects = ioctx.list_objects()
# for obj in objects:
# print(obj.key)
# ioctx.close()
# 读取文件
# ioctx = cluster.open_ioctx('cephfs_data')
# data = ioctx.read("OS.pdf")
# f_download = open("OS_download.pdf", "wb")
# f_download.write(data)
# f_download.close()
# ioctx.close()

可以看到,osd存储量一直在上升,说明上传有效果。也可以通过指令查看一个pool存储的文件。
不过直连RADOS是不太好的,测试发现,上传完毕之后并不会进行4MiB为单位的文件分片。查询相关文档之后知道这样直连RADOS,分片阈值时128MiB。
我们可以挂rbd(块存储)或者用s3(对象存储,需要部署对象网关RGWS并创建账号)来更好地使用ceph。

- 部署RGWS网关
如果你不需要使用S3对象存储,那么这一步可以先跳过。
radosgw-admin realm create --rgw-realm=myorg --default
radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn-east-1 --master --default
ceph orch apply rgw myorg cn-east-1 --placement="cephtest1 cephtest2 cephtest3"
静待3分钟左右,然后输入docker ps | grep rgw。

使用cephadm shell进入ceph,然后添加用户:
radosgw-admin user create --uid="ceph-rgw-testuser" --display-name="Soulter"
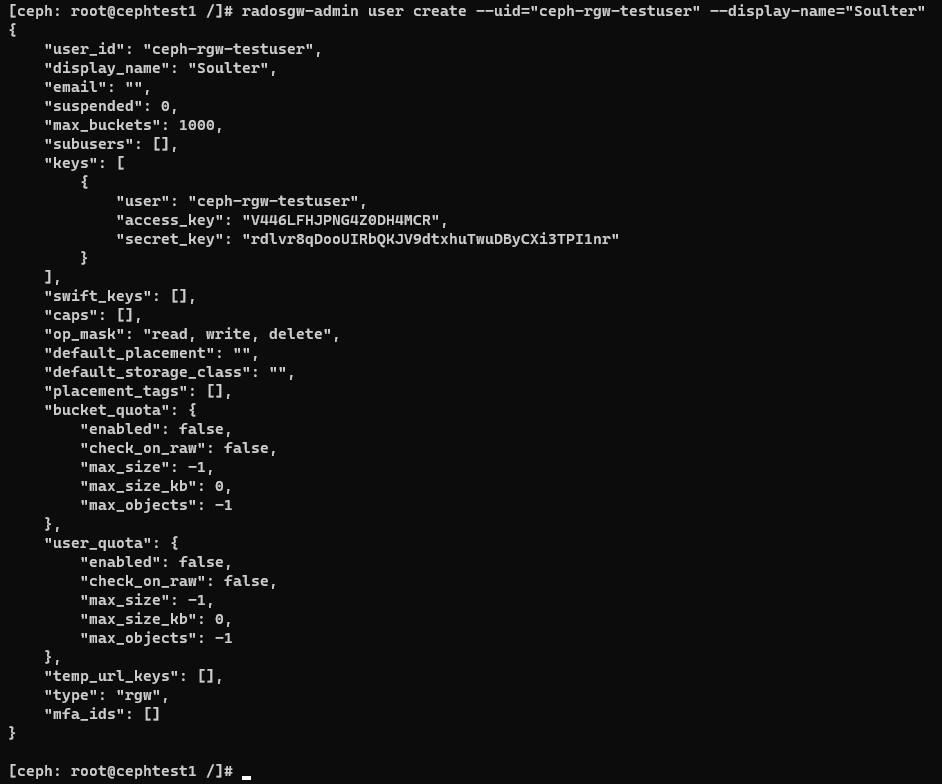
可以看到,我们刚刚在对象网关创建了一个新的用户。其实access_key和secret_key就已经类似于那些云厂商提供的key了。
下面使用一下对象存储吧!
pip install boto
import boto
import boto.s3.connection
access_key = 'V446LFHJPNG4Z0DH4MCR'
secret_key = 'rdlvr8qDooUIRbQKJV9dtxhuTwuDByCXi3TPI1nr'
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = 'cephtest1', port = 80,
is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
# 创建Bucket
bucket = conn.create_bucket('ceph-s3-bucket')
for bucket in conn.get_all_buckets():
print ("{name}".format(name = bucket.name))

(到这里我们就可以开发出七牛云等云厂商的对象存储服务了)
- 部署rbd
# 创建pool
ceph osd pool create rbd 32 32
# 验证
ceph osd pool ls
# pool启用rbd
ceph osd pool application enable rbd rbd
# 初始化
rbd pool init -p rbd
# 创建img映像(可以多创)
rbd create rbd-data-img1 --size 1G --pool rbd --image-format 2 --image-feature layering
# 验证
rbd ls --pool rbd -l
客户端使用rbd:
# 需要先安装ceph-common
# 前两条可选,如果你配置了epel源那就不需要了。
yum install epel-release
yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y
yum install ceph-common
NOTE:客户端的/etc/ceph/文件夹下的ceph.conf 和 ceph.client.admin.keyring需要和集群的相同。
rbd -p rbd map rbd-data-img1

然后我们就可以用lsblk指令看到刚刚映射的盘了。

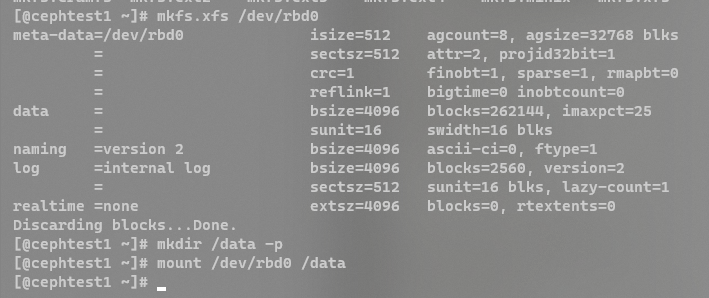
# 格式化磁盘并挂载
mkfs.xfs /dev/rbd0
mkdir /data -p
mount /dev/rbd0 /data
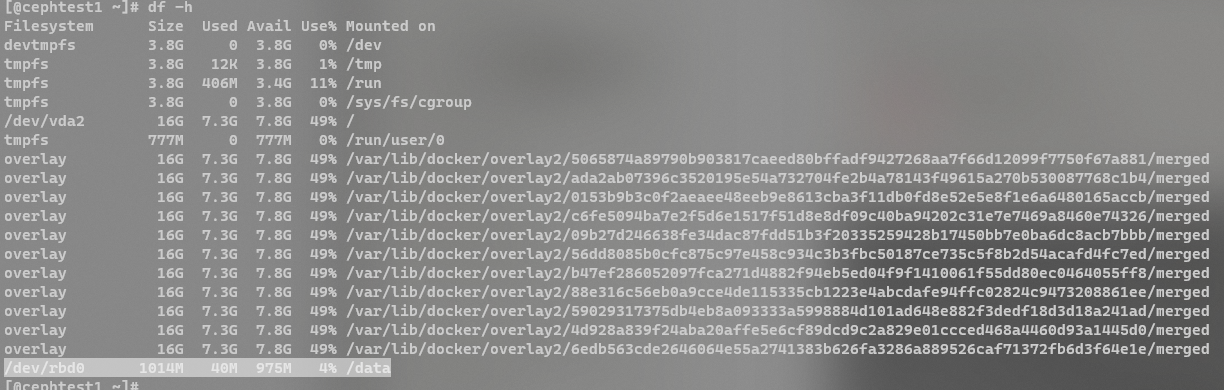
(到这里我们就可以开发出阿里网盘的挂载盘的功能了)
自动负载均衡脚本
本脚本主要使用osdmaptool这一个工具来解决pg分布不均衡的问题,从外层看,解决的是磁盘占用率不均衡的问题。
osdmaptool 工具通过一些参数来输出需要优化的信息。
命令
osdmaptool {osdmap_filename} --upmap out.txt [–upmap-pool ] [–upmap-max ] [–upmap-deviation ]
其中
upmap-pool :指定需要优化均衡的存储池名
upmap-max: 指定一次优化的数据条目,默认100,可根据环境业务情况调整该值,一次调整的条目越多,数据迁移会越多,可能对环境业务造成影响。
max-deviation:最大偏差值,默认为0.01(即1%)。如果OSD利用率与平均值之间的差异小于此值,则将被视为完美。
下面的代码主要实现了定时启动、决定何时调用osdmaptool。
import os
import time
from subprocess import Popen, TimeoutExpired, PIPE
import datetime
UPMAP_MAX = 100 # 最大优化指令行数
UPMAP_DEVIATION = 1 # 最大偏差值,如果OSD利用率与平均值之间的差异小于此值,将被认为完美而不优化。
POOL = "cephfs_data" # pool名称。后期可以做成轮询所有pool或指定的n个pool
ROUND_SECONDS = 1000 # 脚本定时启动时间
FG_COLORS = {
"black": "30",
"red": "31",
"green": "32",
"yellow": "33",
"blue": "34",
"purple": "35",
"cyan": "36",
"white": "37",
"default": "39",
}
BG_COLORS = {
"black": "40",
"red": "41",
"green": "42",
"yellow": "43",
"blue": "44",
"purple": "45",
"cyan": "46",
"white": "47",
"default": "49",
}
LEVEL_INFO = "INFO"
LEVEL_WARNING = "WARNING"
LEVEL_ERROR = "ERROR"
LEVEL_CRITICAL = "CRITICAL"
level_colors = {
"INFO": "green",
"WARNING": "yellow",
"ERROR": "red",
"CRITICAL": "purple",
}
def get_osd_df(pool):
osd_df = os.popen("cephadm shell ceph osd df").read()
osd_df = osd_df.split("\n")[1:]
osd_df = [line.split(" ") for line in osd_df]
osd_df = [[word for word in line if word != ""] for line in osd_df]
osd_df = osd_df[:-3]
# print("osd_df:")
# print(osd_df)
ave_used = 0
for osd in osd_df:
ave_used += float(osd[16])
ave_used /= len(osd_df)
log(f"pool {pool} OSD Average used: " + str(ave_used), level=LEVEL_INFO)
#print("Average used: " + str(ave_used))
osd_to_upmap = []
for osd in osd_df:
if osd[19] != "UP":
continue
# print("osd: " + str(osd))
if abs(float(osd[16]) - ave_used) > UPMAP_DEVIATION:
osd_to_upmap.append(osd[0])
# print("OSD to upmap: " + str(osd_to_upmap))
if len(osd_to_upmap) > 0:
log(f"Found unbalanced OSD in pool {pool}: " + str(osd_to_upmap), level=LEVEL_INFO)
# os.popen("cephadm shell ceph osd getmap -o osd.map").read()
# p = Popen(["cephadm", "shell"], stdin=PIPE, stdout=PIPE, stderr=PIPE)
# p.stdin.write(b"ceph osd getmap -o osd.map\n")
# p.stdin.write(b"osdmaptool osd.map --upmap " + b" ".join(osd_to_upmap) + b" --upmap-pool " + bytes(POOL, encoding="utf-8") + b" --upmap-max " + bytes(str(UPMAP_MAX), encoding="utf-8") + b" --upmap-deviation " + bytes(str(UPMAP_DEVIATION), encoding="utf-8") + b"\n")
# p.stdin.write(b"exit\n")
# p.stdin.close()
# print(p.stdout.read().decode("utf-8"))
# print(p.stderr.read().decode("utf-8"))
t = os.popen(f"cephadm shell -- bash -c 'ceph osd getmap -o osd.map; osdmaptool osd.map --upmap t.out --upmap-pool {pool} --upmap-max {UPMAP_MAX} --upmap-deviation {UPMAP_DEVIATION}; cat t.out'").read()
upmap_cmds = []
l = t.split("\n")
for line in l:
if line.startswith("ceph osd pg-upmap-item"):
# print(line)
upmap_cmds.append(line)
log(f"Upmap commands: " + str(upmap_cmds), level=LEVEL_INFO)
f_name = f"osd_upmap_{time.time()}"
if len(upmap_cmds) > 0:
with open(f_name, "w") as f:
f.write("\n".join(upmap_cmds))
# 执行
t = os.popen(f"chmod +x {f_name} && ./{f_name}").read()
log(f"Upmap done. Result: " + str(t), level=LEVEL_INFO)
else:
log(f"No upmap commands generated, skip.", level=LEVEL_INFO)
# 这里可以不用理解。这只是一个打印log的函数。
def log(
msg: str,
level: str = "INFO",
tag: str = "System",
fg: str = None,
bg: str = None,
max_len: int = 10000):
if len(msg) > max_len:
msg = msg[:max_len] + "..."
now = datetime.datetime.now().strftime("%m-%d %H:%M:%S")
pre = f"[{now}] [{level}] [{tag}]: {msg}"
if level == "INFO":
if fg is None:
fg = FG_COLORS["green"]
if bg is None:
bg = BG_COLORS["default"]
elif level == "WARNING":
if fg is None:
fg = FG_COLORS["yellow"]
if bg is None:
bg = BG_COLORS["default"]
elif level == "ERROR":
if fg is None:
fg = FG_COLORS["red"]
if bg is None:
bg = BG_COLORS["default"]
elif level == "CRITICAL":
if fg is None:
fg = FG_COLORS["purple"]
if bg is None:
bg = BG_COLORS["default"]
print(f"\033[{fg};{bg}m{pre}\033[0m")
if __name__ == "__main__":
while True:
log("Balance check start", level=LEVEL_INFO, bg=BG_COLORS["yellow"])
get_osd_df(pool=POOL)
log("Balance check end", level=LEVEL_INFO, bg=BG_COLORS["yellow"])
time.sleep(ROUND_SECONDS)
效果(由于测试集群负载不大,因此效果可能不太显著,但是是倾向于有效果的。):
原来:
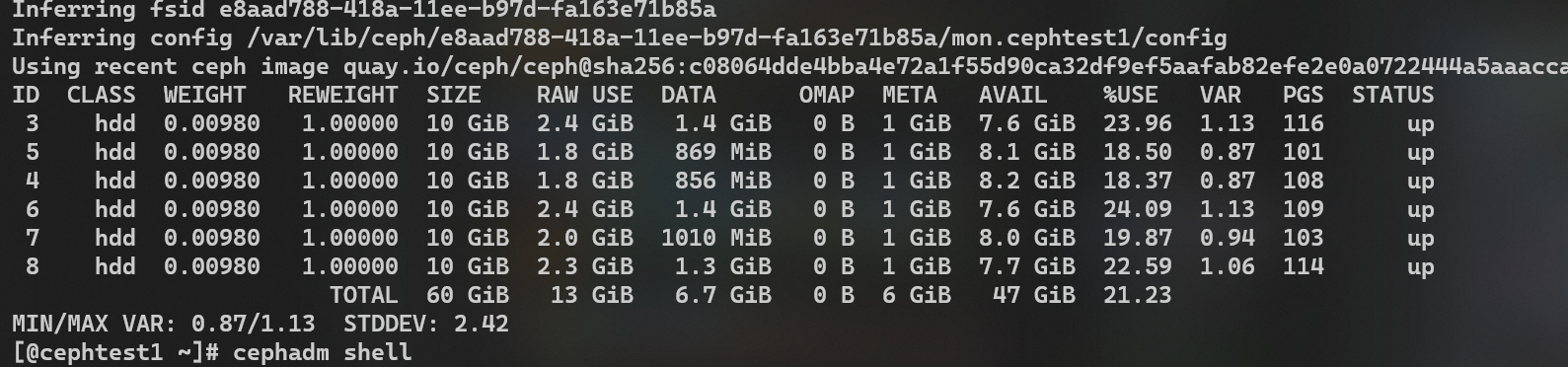
优化后:

整理一些资源
Ceph Luminous手动解决pg分布不均衡问题 - 简书 (jianshu.com)
ceph 数据均衡(balance)_ceph balancer_菜猿猿的博客-CSDN博客
kernel_awsome_feature/Ceph/Ceph分层存储优化策略研究与实现.pdf at main · 0voice/kernel_awsome_feature (github.com)理解 QEMU/KVM 和 Ceph(1):QEMU-KVM 和 Ceph RBD 的 缓存机制总结 - SammyLiu - 博客园 (cnblogs.com)Ceph 发展十年的教训:文件系统不适合作为分布式存储后端_软件工程_Murat Demirbas_InfoQ精选文章cephAdm部署ceph集群 - 掘金 (juejin.cn)
Ceph的Python接口 - salami_china - 博客园 (cnblogs.com)
ceph 对象存储查询对象数据 - 殇™ - 博客园 (cnblogs.com)